vibe coding won't save you
why fundamentals still matter in the age of agentic ai.
2026-04-12 · maithili gulati & russell jiang · first published with datasoc
Vibe coding is a great way to make sure nobody understands what is going on. It might fly under the radar for frontend — but in data science, that's a liability.
01 coding is a commodity
AI has made code a commodity. Anyone can import scikit-learn. Anyone can prompt their way to a working model. But functional code is not the same as valid analysis, and this distinction matters more than it ever has.
At its core, data science is about making claims to other people — and having people act on them. When these claims are wrong, the decisions that follow are wrong too. The differentiator was never who could write the code, it was always who could reason about whether the answer is right.
The market has noticed this shift. While technical skills may get you through the door, only interpretive and integrative data skills will get you hired. Hiring managers aren't just looking for people who can write a query. The ones who stand out are the ones who speak in hypotheses and prove it through results. As one senior AI engineer puts it, you cannot be a "General Importer" — someone who only imports sklearn and runs .fit() and .predict(). Very soon, an AI agent may do that part for us. [1]
This shows up in job postings too. Machine learning skills appear in 77% of data scientist job postings (2025) [2], but running models isn't the bar. Statistics and ML together ranked first across all 101 job postings analysed in 2026 — the same position they held in 2025. [3] What employers are consistently selecting for is reasoning, not just simple implementation.
02 ai can write the code. it can't tell you if it's valid
Here's what AI is genuinely good at: getting you to a working implementation quickly. What it can't do is tell you whether this implementation is statistically appropriate for your problem.
The model doesn't 'know' your data like a human can (not yet, anyways). It doesn't know that your classes are wildly imbalanced, that you are leaking your test set, or that the loss function is simply wrong for the task. It will confidently give you code that runs perfectly, without any indication that something is off.
Amazon's scrapped recruiting program is a canonical example of this going wrong at scale. The company trained its hiring AI on resumes of existing employees, which seemed like standard practice. But Amazon's workforce was disproportionately male, so the algorithm learned that being male was a marker of success. [4] The models penalised terms associated with women, and the initial bias compounded over time, becoming an echo chamber of its own making (not unlike the feedback loops keeping your reels exactly as niche as they are). [5] The code worked. The model trained. The outputs were wrong. Nobody caught it because catching it requires something AI doesn't have: an understanding of what the data actually represents and who it excludes. This is the failure mode vibe coding bakes in. You get a model that runs. You don't get a model you can trust.
03 knowing when the model is wrong
Some of the most important skills in data science come from diagnosing models, not just building them.
Take gradient descent. When you prompt AI to optimise, it'll do it. But do you know what a healthy loss curve looks like? Can you tell the difference between a model converging properly and one that's oscillating, or plateauing early? Without that intuition, you have no way to know whether the training process is doing what you think it's doing.
Or take overfitting. The classic symptom is a validation loss that climbs while training loss keeps falling. But to actually diagnose it — to know whether you need more data, stronger regularisation, a simpler architecture, or to revisit your feature engineering — you need to understand the bias-variance tradeoff. Googling "my val loss is going up" gets you a list of possible causes. Understanding the mechanics tells you which one applies to your situation.
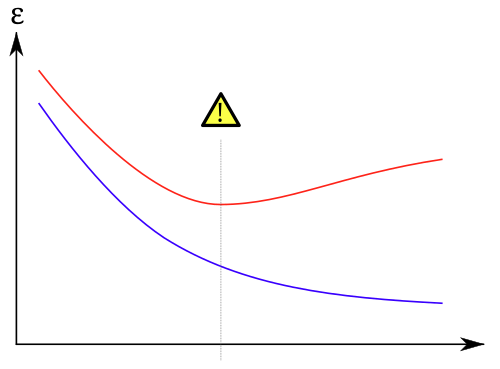
Then there's the problem that breaks things most in production: hypothesis testing. A result that looks statistically significant isn't necessarily meaningful. You need the intuition to know when a result is real and when it's noise — understanding p-values, effect sizes, confidence intervals, and when you simply need more data. [6]
A data scientist who reports a "significant" A/B test result without checking effect size, or who doesn't account for multiple comparisons, can send an organisation down the wrong path with complete statistical cover.
Mathematical intuition is your error-detection layer. Without it, you have no way to audit your own work.
04 the agentic shift raises the stakes
All of this is already a problem when you're the one running the code. It gets considerably worse when the code runs itself.
We're in the middle of a shift from generative AI tools you interact with, to agentic systems that make decisions autonomously. In a traditional workflow, there's a human in the loop at each step — someone who can sanity-check the output before it flows downstream. Agentic pipelines remove that checkpoint. They chain model outputs together automatically, passing results from one step to the next without pausing for review.
The problem is that if you put garbage in, you will almost certainly get garbage out. Most multi-agent systems don't fail because the models are bad. They fail because we compose them as if probability doesn't compound. Even a high-performing agent with a 98% per-task success rate, chained through multiple steps, can see overall system accuracy degrade to 90% or lower. [7]
"if your AI model has a 1% error rate and you plan over 5,000 steps, that 1% compounds like compound interest"— deepmind ceo demis hassabis [8]
This renders outcomes effectively random. Snowflake's director of AI infrastructure frames this as the defining challenge of 2026: "it will be very hard to rely on agents if we don't have a way of systematically measuring their accuracy." [9]
This is where a bad statistical assumption at step one becomes catastrophic. Single agents can make inconsistent decisions from fragmented data, while multi-agent systems lose coordination and propagate errors silently through the entire workflow. McKinsey found that nearly two-thirds of enterprises have experimented with agents, but fewer than 10 percent have scaled them to deliver tangible value, with data quality and faulty assumptions as the primary blocker. [10]

The skill being valued right now isn't "can you implement an agent." It's "can you reason about what happens when this system fails." That's a fundamentally statistical question.
05 reframe the maths
There's a temptation to treat mathematical foundations as gatekeeping — the hard stuff you get through before you're allowed to do the interesting work. That framing gets it backwards.
The maths is not the prerequisite. The maths is the edge.
Vibe coding gets you to roughly 80% of a working solution. For many tasks, that's fine. But data science is a field built on making claims about the world and having people act on them. The ability to explain why a result shouldn't drive action — to push back on your own model before someone else has to — is what separates junior practitioners from senior ones. In an agentic world, wrong decisions don't just sit in a notebook. They scale automatically.
Causal inference is increasingly being flagged as a highly sought-after skill [3] — not because the tooling changed, but because autonomous systems need someone who can reason about whether a correlation actually means anything. The problems you're being asked to solve are getting harder, the stakes are higher, and the gap between someone who can implement and someone who can reason is getting wider.
The models are getting smarter. So should you ■
06 references :P
- 1.Bendimerad, S. (2025). Data Science in 2026: Is It Still Worth It? Towards Data Science.
- 2.365 Data Science. (2025). Data Scientist Job Outlook 2025.
- 3.Choo, D. (2026). 2026 vs. 2025 Data Science Job Market.
- 4.Cangrade. (2023). Hiring Bias Gone Wrong: Amazon Recruiting Case Study.
- 5.University of Maryland. (2018). The Problem With Amazon's AI Recruiter.
- 6.Careery. (2026). How to Become a Data Scientist in 2026.
- 7.O'Reilly. (2026). The Hidden Cost of Agentic Failure.
- 8.ZLTI. (2025). Federal Agentic AI: How Data Solves the Compounding Error Problem.
- 9.Snowflake. (2025). AI + Data Predictions 2026.
- 10.McKinsey. (2026). Building the Foundations for Agentic AI at Scale.